Ihre Seite ist Google bekannt und landet trotzdem nicht im Index
Das Frustrierende an diesem Problem: In der Google Search Console ist Ihre Seite längst bekannt und gecrawlt – sie taucht aber einfach nicht in den Suchergebnissen auf. „Eigentlich ist doch alles da.“ In diesem SEO-Ratgeber deute ich mit Ihnen den Status „Gecrawlt – zurzeit nicht indexiert“, gehe jede mögliche Ursache durch und liefere zu jeder eine konkrete Lösung. Die Tool-Grundlagen selbst – Einrichtung, Property, Verifizierung – setze ich voraus; die erkläre ich im Ratgeber zur Google Search Console.
🎯 Das Wichtigste in Kürze
- „Gecrawlt – zurzeit nicht indexiert“ ist fast immer ein Qualitätssignal: dünner Inhalt, Duplikate oder schwache interne Verlinkung – nicht die Technik.
- „Gefunden – zurzeit nicht indexiert“ ist meist ein Crawl-Budget- oder Server-Problem: Google kennt die URL, kam aber noch nicht zum Crawlen.
- Die Reihenfolge zählt: erst Technik-Blocker ausschließen (noindex, robots.txt, Canonical, Soft 404, 5xx), dann den Status lesen, dann den Inhalt verbessern – und erst zuletzt die Indexierung anstoßen.
- Geduld statt Klick-Spam: Wiederholtes „Indexierung beantragen“ ersetzt keine behobene Ursache, und Google nennt keine garantierten Indexierungs-Zeiträume.
💡 Kurz erklärt: Was bedeutet der Status?
Wie kommt eine Seite überhaupt in den Google-Index?
Bevor wir die Status deuten, lohnt der Blick auf den Ablauf. Bis eine Seite in der Suche erscheint, durchläuft sie drei Stufen: Erst das Crawling (der Googlebot besucht die Seite und liest den Inhalt), dann die Indexierung (Google nimmt die Seite in seinen Index auf), und erst danach das Ranking (die Seite kann zu Suchanfragen ausgespielt werden). Entscheidend ist der häufigste Denkfehler: „Gecrawlt“ heißt nicht „indexiert“. Google kann eine Seite besuchen und sich trotzdem dagegen entscheiden, sie in den Index aufzunehmen.
Welcher dieser Status für eine bestimmte URL gilt, lesen Sie im Seitenindexierungs-Bericht der Search Console ab – nicht im abgelösten „Abdeckung“-Bericht. Jede nicht indexierte Seite trägt dort einen konkreten Status mit Begründung; eine Erklärung der einzelnen Status liefert auch die Google-Dokumentation zum Seitenindexierungs-Bericht. Die folgende Tabelle ordnet die wichtigsten ein – mit Bedeutung, häufigster Ursache und Sofort-Maßnahme.
| Status (in der Search Console) | Bedeutung | Häufigste Ursache | Sofort-Maßnahme |
|---|---|---|---|
| Gecrawlt – zurzeit nicht indexiert | Google war da, hat aber nicht indexiert | Dünner Inhalt, Duplikat, schwache interne Verlinkung | Inhaltsqualität und interne Verlinkung verbessern (siehe unten) |
| Gefunden – zurzeit nicht indexiert | Google kennt die URL, hat noch nicht gecrawlt | Crawl-Budget zu niedrig, Server überlastet, fehlt in Sitemap | Server und Sitemap prüfen, abwarten |
| Durch „noindex“-Tag ausgeschlossen | Aktiver Indexierungs-Stopp | noindex im Meta-Tag oder HTTP-Header | noindex entfernen |
| Durch robots.txt blockiert | Crawling unterbunden | Regel in der robots.txt | robots.txt-Regel anpassen |
| Seite mit Weiterleitung | Die URL leitet weiter | beabsichtigte oder ungewollte Redirects | Ziel-URL indexieren lassen |
| Duplikat – Google wählte andere kanonische Seite | Canonical-Konflikt | kanonisches Tag zeigt woanders hin | Canonical korrigieren |
| Soft 404 | „200 OK“, wirkt aber leer oder fehlerhaft | dünne oder Fehlerseite mit 200-Status | echten Inhalt liefern oder sauberes 404 |
| Serverfehler (5xx) | Server antwortete mit einem Fehler | Überlastung, Fehlkonfiguration | Server- und Hoststatus beheben |
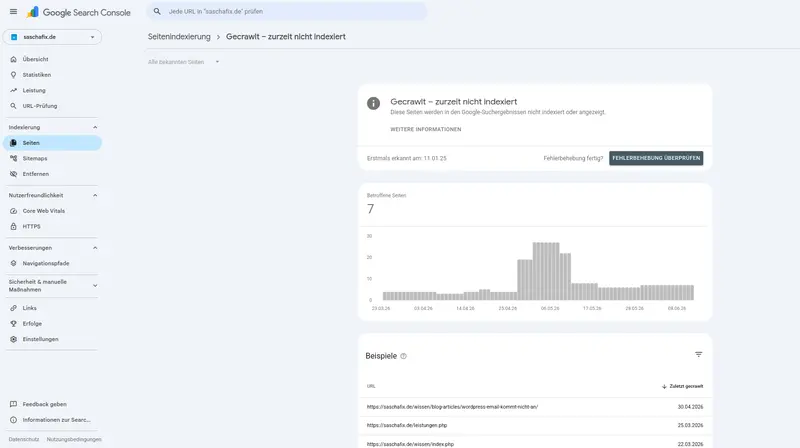
Was bedeutet „Gecrawlt – zurzeit nicht indexiert“?
Dieser Status (englisch „crawled currently not indexed“) sagt: Google hat die Seite besucht, sie aber bewusst (noch) nicht in den Index aufgenommen. Bei „Gecrawlt – zurzeit nicht indexiert“ liegt das Problem fast immer an der Inhaltsqualität, nicht an der Technik. Google hat die Seite gesehen und entschieden, dass sie aktuell keinen Mehrwert gegenüber bereits indexierten Seiten bietet. Das ist also ein Qualitäts- und Relevanzsignal, kein Crawling-Fehler. Die vier häufigsten Auslöser sehen wir uns einzeln an.
Ursache 1 – Dünner Inhalt (Thin Content)
Die Seite hat zu wenig substanziellen Inhalt: ein paar Zeilen Text, eine reine Bildergalerie oder eine Platzhalterseite. Solcher Thin Content gibt Google kaum Gründe, die Seite zu indexieren. Die Lösung ist unbequem, aber wirksam: Schreiben Sie bessere, hilfreichere Texte, die eine konkrete Frage vollständig beantworten. Eine Seite, die ein Thema wirklich abschließend behandelt, hat deutlich bessere Chancen auf einen Indexplatz.
Ursache 2 – Duplicate Content oder sehr ähnliche Seiten
Wenn mehrere Ihrer Seiten denselben oder fast denselben Inhalt tragen, behält Google meist nur eine davon im Index – die anderen landen unter „Gecrawlt – zurzeit nicht indexiert“. Typische Fälle sind Filter- und Sortier-URLs, leicht variierte Standorttexte oder Produktseiten mit identischen Beschreibungen. Lösung: Geben Sie jeder Seite einen eigenständigen Schwerpunkt, oder führen Sie sehr ähnliche Seiten zu einer starken Seite zusammen. Hilfreich ist hier, vorab mit einer sauberen die richtige Suchintention zu treffen, damit nicht zwei Seiten dasselbe Bedürfnis bedienen.
Ursache 3 – Schwache interne Verlinkung
Eine Seite, auf die kaum interne Links zeigen, wirkt für Google unwichtig – fast wie eine vergessene Ecke Ihrer Website. Wenn weder Menü noch andere Artikel auf die Seite verweisen, fehlt das Signal „diese Seite ist relevant“. Die Lösung: die interne Verlinkung verbessern und thematisch passende Seiten gezielt aufeinander verweisen lassen. Schon einige starke interne Links können eine festhängende Seite in den Index bringen.
Ursache 4 – Inhalte, die nicht mehr aktuell oder relevant sind
Veraltete Seiten – alte Aktionen, abgelaufene Termine, überholte Anleitungen – stuft Google als wenig hilfreich ein und hält sie aus dem Index. Lösung: Aktualisieren Sie den Inhalt spürbar, ergänzen Sie aktuelle Informationen, oder leiten Sie endgültig veraltete Seiten auf eine passende, gepflegte Seite weiter.
Was tun? Die Lösung gebündelt
Bei „Gecrawlt – zurzeit nicht indexiert“ führt der Weg fast immer über bessere Inhalte: Machen Sie die Seite spürbar hilfreicher als das, was schon im Index steht, geben Sie ihr einen eigenständigen Schwerpunkt und sorgen Sie für interne Links von relevanten Seiten. Erst danach lohnt es sich, die Indexierung erneut anzustoßen. Es nützt nichts, eine unveränderte dünne Seite wieder und wieder anzumelden – dazu gleich mehr.
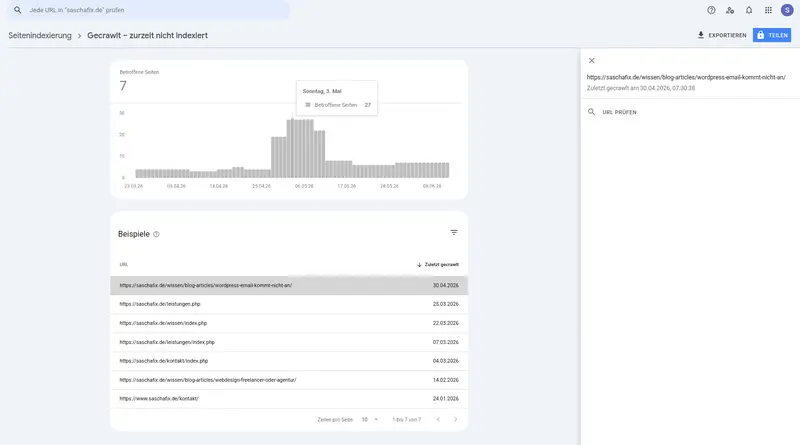
Was bedeutet „Gefunden – zurzeit nicht indexiert“?
Hier ist die Abgrenzung zu „Gecrawlt“ entscheidend: Bei „Gefunden – zurzeit nicht indexiert“ (in manchen Ansichten „Entdeckt – zurzeit nicht indexiert“) kennt Google die URL zwar, kam aber noch gar nicht zum Crawlen. „Gefunden – zurzeit nicht indexiert“ ist oft ein Crawl-Budget- oder Server-Problem: Google kennt die URL, kam aber noch nicht zum Crawlen. Während bei „Gecrawlt“ schon ein Besuch stattfand, steht die Seite hier noch in der Warteschlange. Die drei typischen Auslöser:
Ursache 1 – Crawl-Budget zu niedrig oder sehr große Website
Google crawlt nicht unbegrenzt: Pro Website gibt es ein gewisses Crawl-Budget. Bei sehr großen Websites mit tausenden URLs – oder vielen unwichtigen, automatisch erzeugten Seiten – reicht das Budget nicht für alles, und einzelne Seiten warten lange. Lösung: Räumen Sie unnötige URLs aus (Parameter-Seiten, leere Kategorien) und stärken Sie wichtige Seiten durch interne Links, damit Google sie priorisiert.
Ursache 2 – Server war überlastet oder zu langsam
Reagiert Ihr Server beim Crawlen zu langsam oder fällt zeitweise aus, drosselt Google das Crawling, um die Website nicht weiter zu belasten. Eine dauerhaft träge Seite kann so im Status „Gefunden“ hängen bleiben. Achten Sie auf schnelle Antwortzeiten und solide Hosting-Leistung; auch gute Core Web Vitals beziehungsweise eine niedrige Ladezeit helfen indirekt, weil ein schneller Server mehr Crawl-Kapazität bekommt. Wie Sie diese Werte messen und gezielt verbessern, zeigt der Ratgeber Core Web Vitals optimieren.
Ursache 3 – Seite fehlt in der XML-Sitemap oder ist schwer auffindbar
Wenn eine URL weder in der Sitemap steht noch intern gut verlinkt ist, findet Google sie nur mühsam – und stellt sie hinten in die Warteschlange. Lösung: Nehmen Sie wichtige Seiten in die XML-Sitemap auf und verlinken Sie sie von zentralen Seiten Ihrer Website aus.
Was tun?
Bei „Gefunden – zurzeit nicht indexiert“ helfen drei Hebel: ein stabiler, schneller Server, eine aufgeräumte URL-Struktur und eine vollständige Sitemap mit guter interner Verlinkung. Anschließend gilt vor allem Geduld – in der Regel holt Google diese URLs nach, sobald wieder Crawl-Kapazität frei ist.
Warum indexiert Google meine Seite nicht? (Ursachen im Überblick)
Die bisherigen Status drehten sich um Qualität und Crawl-Kapazität. Daneben gibt es technische Hart-Blocker, die das Indexieren aktiv verhindern – unabhängig davon, wie gut Ihr Inhalt ist. Wenn Sie sich fragen „seite nicht indexiert, was tun“, sind das die drei Stellen, die Sie zuerst ausschließen sollten. Diese Indexierungsprobleme bei Google sind oft mit wenigen Klicks behoben.
noindex-Tag auf der Seite
Ein noindex-Tag weist Google ausdrücklich an, die Seite nicht in den Index aufzunehmen – im Meta-Tag im Quelltext oder im HTTP-Header. Es ist die häufigste Ursache, wenn eine Seite gar nicht erst eine Chance bekommt. Prüfen Sie es im URL-Prüftool oder im Quelltext und entfernen Sie das noindex, wenn die Seite indexiert werden soll. Bei WordPress steckt es oft versteckt in einer Plugin-Einstellung oder in der globalen „Suchmaschinen abhalten“-Checkbox.
robots.txt blockiert die Seite
Die robots.txt kann dem Googlebot das Crawlen ganzer Verzeichnisse verbieten. Steht die URL hinter einer „Disallow“-Regel, kann Google den Inhalt nicht lesen und damit auch nicht sauber indexieren. Prüfen Sie die robots.txt unter ihre-domain.de/robots.txt und lösen Sie versehentliche Sperren auf. Wichtig: robots.txt steuert das Crawlen, nicht das Indexieren – Google kann eine per robots.txt blockierte URL trotzdem im Index führen, wenn externe Seiten auf sie verweisen. In diesem Fall erscheint die URL ohne Seitenbeschreibung, weil Google den Inhalt nicht lesen durfte.
Canonical-Tag zeigt auf eine andere URL
Ein Canonical-Tag (kanonisches Tag) sagt Google, welche von mehreren ähnlichen URLs die „Hauptversion“ ist. Zeigt das Canonical Ihrer Seite versehentlich auf eine andere URL, indexiert Google die andere – Ihre Seite erscheint als „Duplikat ohne kanonische URL“. Das passiert oft bei CMS-Vorlagen oder Plugins, die ein falsches Canonical setzen. Lösung: Stellen Sie sicher, dass jede Seite per Canonical auf sich selbst verweist, sofern sie eigenständig indexiert werden soll – und nur Duplikate auf ihre Hauptversion.
Soft 404, Server-5xx und JavaScript: die technischen Sonderfälle
Jetzt wird es technischer. Als Entwickler schaue ich bei hartnäckigen Fällen genau auf diese drei Sonderfälle – sie sind für KMU-Betreiber selten offensichtlich, erklären aber viele „url nicht indexiert“-Rätsel. Wer das systematisch durchgehen will, dem hilft ein vollständiges technisches SEO-Audit. Die Crawling- und Indexierungs-Grundlagen dazu beschreibt auch Google Search Central zum Crawling und Indexieren.
Soft 404 – Seite liefert „200 OK“, wirkt aber leer oder fehlerhaft
Ein Soft 404 entsteht, wenn eine Seite technisch den HTTP-Statuscode „200 OK“ zurückgibt, inhaltlich aber wie eine Fehler- oder Leerseite wirkt – etwa „Keine Ergebnisse gefunden“ oder eine fast leere Vorlage. Google wertet so eine Seite trotz 200-Status als 404 und nimmt sie nicht in den Index auf. Lösung: Liefern Sie auf solchen URLs echten, hilfreichen Inhalt – oder geben Sie für wirklich nicht existierende Seiten sauber den Status 404 oder 410 zurück.
Serverfehler (5xx) und falsche HTTP-Statuscodes
Antwortet Ihr Server beim Googlebot-Besuch mit einem Serverfehler aus der 5xx-Reihe (etwa 500 oder 503), kann Google die Seite nicht abrufen. Treten solche Serverfehler wiederholt auf, fliegt die Seite aus der Indexierungswarteschlange und wird nicht indexiert. Wichtig ist deshalb, dass der Server auch unter Last und gerade beim Crawlen verlässlich „200 OK“ liefert. Prüfen Sie Server-Logs und den Hoststatus, wenn der Status hartnäckig bleibt.
Wenn Google den Inhalt nicht rendern kann (JavaScript und SSR)
Wird Ihr eigentlicher Inhalt erst per JavaScript im Browser nachgeladen und nicht serverseitig ausgeliefert, „sieht“ Google ihn unter Umständen gar nicht – die gecrawlte Seite wirkt für den Bot fast leer. Das betrifft vor allem moderne Frameworks ohne sauberes Rendering. Die Lösung heißt Server Side Rendering (SSR) oder Prerendering: Der Server liefert den fertigen Inhalt schon im HTML aus, sodass der Googlebot ihn ohne JavaScript lesen kann. Das ist die wichtigste Grundvoraussetzung dafür, dass der Googlebot den Inhalt überhaupt erfassen kann.
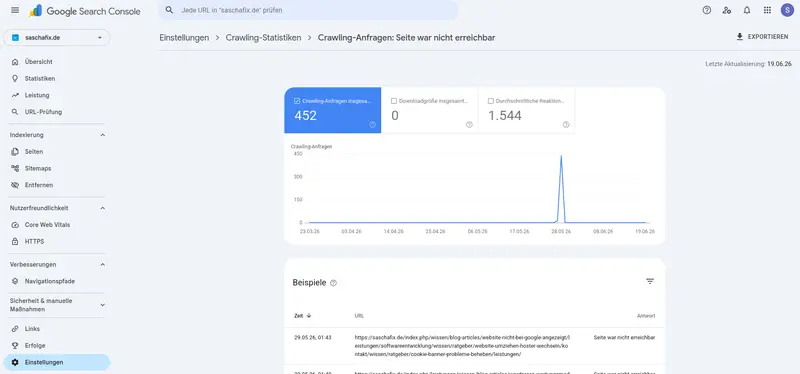
In welcher Reihenfolge prüfe ich, warum eine Seite nicht indexiert wird?
Hier liegt der eigentliche Hebel: Statt wild herumzuprobieren, gehe ich immer dieselbe Reihenfolge durch – von „aktiv blockiert“ zu „zu schwach für den Index“. So schließen Sie die teuren Technikfehler zuerst aus, bevor Sie aufwendig am Inhalt arbeiten. Diese fünf Schritte können Sie eins zu eins übernehmen:
- Technik-Blocker ausschließen: Prüfen Sie mit dem URL-Prüftool, ob ein noindex-Tag oder die robots.txt die Seite blockiert.
- Canonical-Tag prüfen: Stellen Sie sicher, dass das kanonische Tag nicht auf eine andere URL verweist.
- HTTP-Status und Soft 404 prüfen: Liefert die Seite sauber „200 OK“ mit echtem Inhalt (kein Soft 404, kein 5xx)?
- Status im Seitenindexierungs-Bericht lesen: „Gecrawlt“ deutet auf Inhaltsqualität, „Gefunden“ auf Crawl-Budget oder Server.
- Ursache beheben und Indexierung anstoßen: Inhaltsqualität und interne Verlinkung verbessern, dann über das URL-Prüftool die Indexierung beantragen.
Indexierung mit dem URL-Prüftool anstoßen
Erst wenn die Ursache behoben ist, melden Sie die Seite über das URL-Prüftool oben in der Search Console zur erneuten Prüfung an und klicken auf „Indexierung beantragen“. Google nimmt die URL dann in die Crawl-Warteschlange auf – eine Aufnahme in den Index ist damit aber nicht garantiert. Wie Sie das Tool im Detail bedienen, lesen Sie im Ratgeber zur Google Search Console sowie in der offiziellen Hilfe zum URL-Prüftool. Falls Ihre Website überhaupt nicht in Google auftaucht, hilft der Beitrag Website wird gar nicht bei Google angezeigt bei den häufigsten Grundursachen.
⚠️ Mythos: Hilft wiederholtes „Indexierung beantragen“?
Wie lange dauert es, bis Google eine Seite indexiert?
Eine ehrliche Antwort vorweg: Google nennt keine garantierten Zeiträume. Aus der Praxis lassen sich aber Richtwerte ableiten. Eine neue Seite braucht oft ein bis vier Wochen, bis sie im Index erscheint – manchmal schneller, manchmal länger. Nach dem Beheben einer Blockade (etwa einem entfernten noindex) geht es meist zügiger: häufig wenige Tage bis rund zwei Wochen, bis Google die Seite erneut crawlt und neu bewertet.
Das URL-Prüftool kann diesen Prozess beschleunigen, indem es die Seite vorrangig in die Crawl-Warteschlange schiebt – garantieren kann es eine Indexierung jedoch nicht. Geduld gehört bei der Indexierung also dazu: Wichtig ist, die Ursache sauber zu beheben, nicht im Stundentakt nachzuhaken.
Häufig gestellte Fragen
Alles rund um die Indexierung in der Search Console
Zuletzt aktualisiert: 20. Juni 2026 · Lesezeit: ca. 11 Minuten
Über den Autor
Seite hängt trotz aller Prüfungen im Status „nicht indexiert“?
Wenn Sie alle Ursachen geprüft haben und Ihre Seite immer noch nicht im Google-Index landet, schaue ich mir das technisch an – vom Server-Status über das Rendering bis zur internen Verlinkung. Ehrlich, ohne Tricks und ohne Tool-Zwang. Mehr dazu unter SEO und technische Optimierung.